Thoughts

A Strategic Storytelling Tutorial

 17 minute read
17 minute read
Streamlining the mechanics of storytelling makes it easy to focus on the art and craft of narrative.
In the past, I've discussed why stories are fundamental to shaping, communicating, and evangelizing for a design strategy. The stories we tell are grounded in qualitative ethnographic research and bring our participants to life: we champion their wants and needs, bring their voices to the design process and provoke emotional reactions. The dissonance created by those reactions needs to be resolved, so narrative acts as a prompt for difficult conversations through the creative process.
The "telling of the story" to support strategy is an art in itself, as is the curation process and the delivery. Yet I've seen that one of the biggest hurdles to accomplish this lies in logistics even more than the creative portion of the process.
Research generates lots of data, and it can be intimidating to work through the mess to find the gems. Over the years, our team has refined an operational method for organizing ourselves as we prepare stories from the field. I want to share our step-by-step process so others can learn from our deep experience and focus on what matters most—the actual stories themselves.
For additional details on building a research plan and conducting qualitative rather than quantitative research, feel free to download a complimentary copy of How I Teach.
Let's dive in.
Setting up our files, folders, and naming
One of the most important parts of this process is also the most mundane: setting up the folder structure for the content we’re about to generate. Strong file management is key, especially for large quantities of data, so that when you start to weave together narratives, you can find the content, quickly. An additional benefit of a rigid structure like this is that all team members can dive into a project and find the materials immediately.
Our folder structure looks like this:
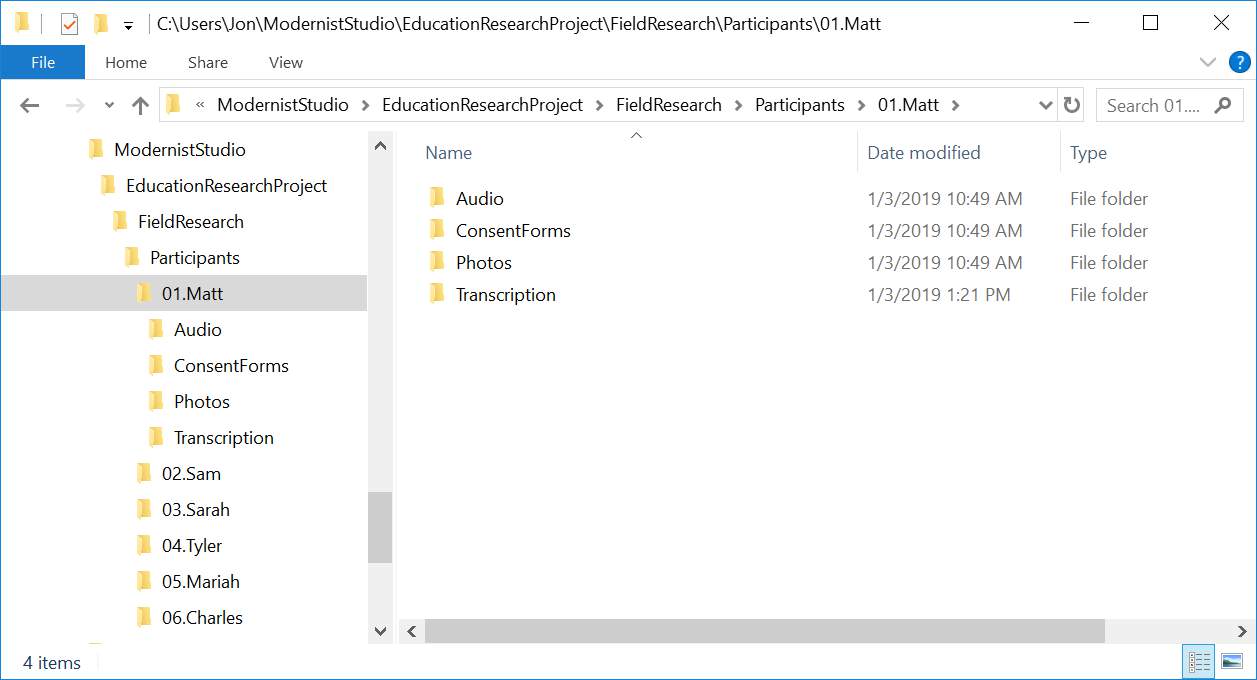
First, we create a parent folder for the project as a whole. Within that, there is a sub-folder for the research participants and inside that is a unique folder for each participant. The folder format is:
[participant number].[participant name]
The raw audio, consent forms, photos, and transcription materials are organized under each participant’s folder.
Recording the Interview
When conducting research, weaudio-record the session (with the participant’s signed consent and a clear understanding of whether the recording will be private, shared anonymously, or shared publicly). The recording becomes the source material for the remainder of synthesis, so it’s important to get this right.
When we can be in person, we use Sony Digital Voice Recorders, which are small and inconspicuous. It's easy to tell when they are recording, because they have a red light on the top that's on only when it is active, and the battery indicator clearly shows how much battery life is left.
The most important factor in selecting a physical voice recorder is the integrated storage and USB connector. When we're in the field, traveling quickly between locations, we don't want to be struggling with cables and connectors—we just plug it into our laptop, and it works.

When we’re remote, we use an online video/audio tool, and leverage their built-in recording capabilities. We try to be tool agnostic, and use whichever tool is simplest for a user to install and manipulate. And even during remote research, we still use a voice recorder, placed next to our computer speaker. This provides a backup; additionally, it gives us what is often a more manageable file as a single audio track.
Immediately after the research session, we copy the audio file to our shared Dropbox project folder— often doing this in the car on the way from one research session to another.
Full verbose transcription
As soon as possible after the research has concluded, we produce a complete transcription of the session with all of the participant’s content presented exactly as spoken. We don’t include obvious verbal ticks, such as "uh" and "um," or anything the interviewer said or asked. We press Enter to indicate a complete thought or idea, often delineated by a pause, intake of breath, topic change, or when a question was asked.
It's tempting at this point to find a third party to do the transcription—it’s inexpensive and would free you up to do other things.
We often choose to transcribe the work ourselves, however, dividing it up among the research team. It takes a time, but has immediate and tangible value, because when we're finished, each of us understands part of the interview intimately, and can "channel" the participant. When we start to craft stories, at least one of us will know each detail inside and out. After transcribing a participant, I can hear their voice in my head, and that voice is lasting—days or even weeks later, I remember their comments, tone, and the inflections of their statements. When a team member asks me a question about them, I can answer it, quickly and completely.
One tool we do use to aid our transcription is called oTranscribe. It's free and simplifies the process with simple key combinations to pause, stop, rewind, slow down or speed up the recording. Fluency in the tool means that we rarely need to stop transcribing and can get through the entire process in just a few passes.
When we do use a paid transcription service, we make sure that it’s transcription provided by a human, not a speech-to-text system. These systems, while mostly accurate, tend to lose the colloquialisms and nuances in human language that help bring experiences to life.
Coding in Excel
After transcribing the audio into a manageable text format, we start coding the text–adding meta-data so we can find it easily once we start moving content around. We need a way to get back to a source when the words are out of the context, similar to how citations work in writing.
We code the text in Excel:
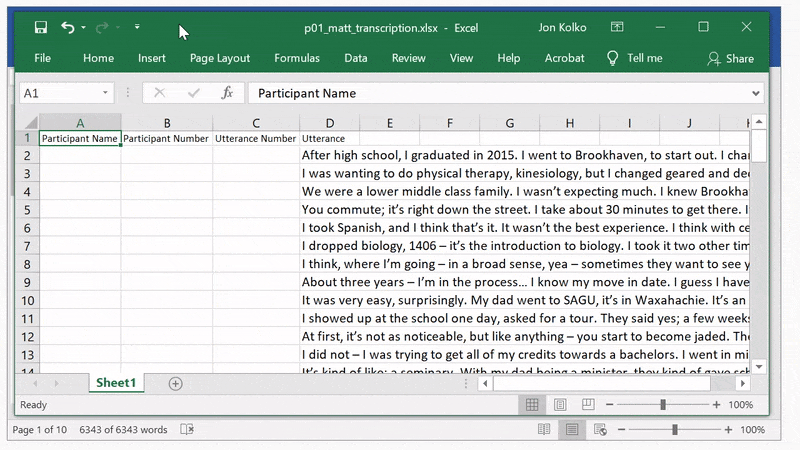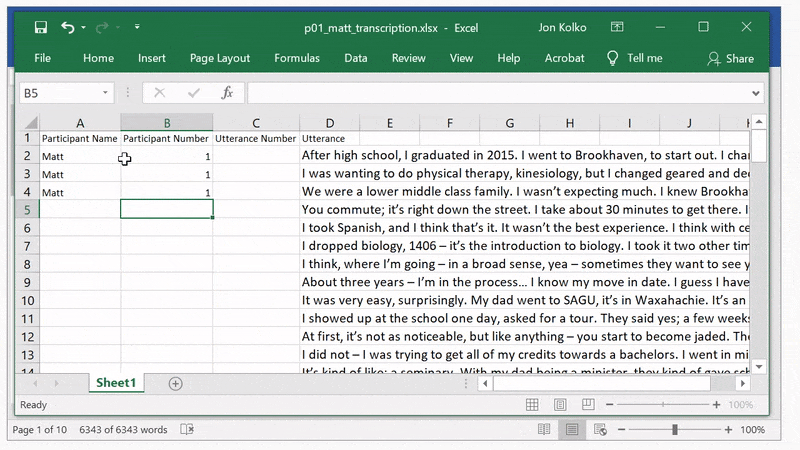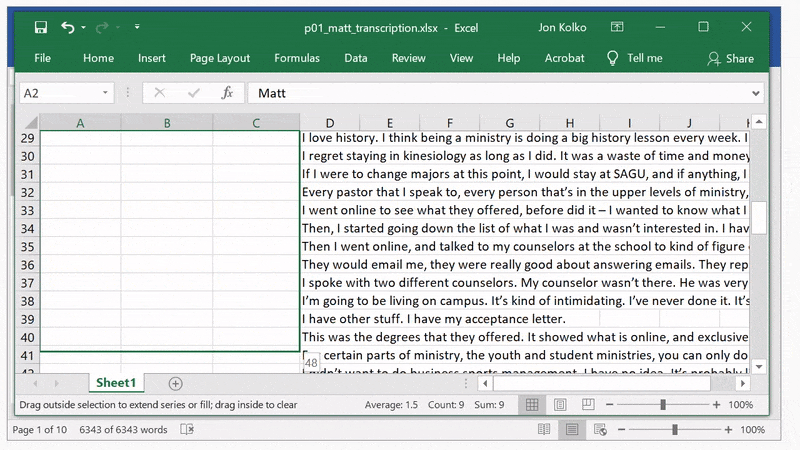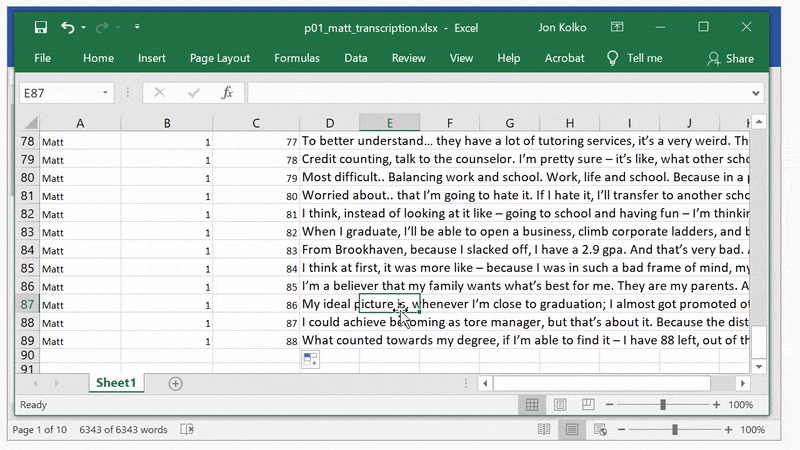
- Copy the entire text transcription and paste it in a new Excel document. You'll see the content flow through the document, and each line break in the Word document becomes a new row in Excel.
- Insert a blank row at the top and three columns to the left of the text.
- Label the first column Participant Name.
- Label the second column Participant Number.
- Label the third column Utterance Number. This will be a series starting with 1 for each participant.
- Finally, label the utterance column Utterance.
Enter three rows of data, giving Excel enough material to work with for duplication, then, drag the bottom right corner of the cell all the way to the bottom, to fill in the remaining data.
Now, you have meta-data about the transcript and each utterance is uniquely referenceable. Write down the last Utterance number, so you can pick up where you left off on the next participant.
Repeat this process for each participant in a new Excel document so that later, when someone asks a question about your work, you can always find the source material, identifying exactly what a person said, and the context for the remark.
Create individual utterance cards
Next, we move from raw data to a format appropriate for meaning-making, physically immersing ourselves in the data on the studio walls. To do so, we print every single utterance on a small piece of paper, which can then be manipulated, grouped, and arranged. Most importantly, they can be intermingled across participants as we make observations and inferences about the research as a whole.
For this step, we re-purpose a feature in Microsoft Word: Mail Merge, which is typically used to create mailing labels. This function works by combining a list of mailing addresses in Microsoft Excel with a layout based on a physical sheet of labels (typically two columns with 10 rows). Instead, we trick it, printing "labels" of each of our utterances on plain paper.
These instructions are for Windows, but the process is very similar on a Mac.
Set up your document
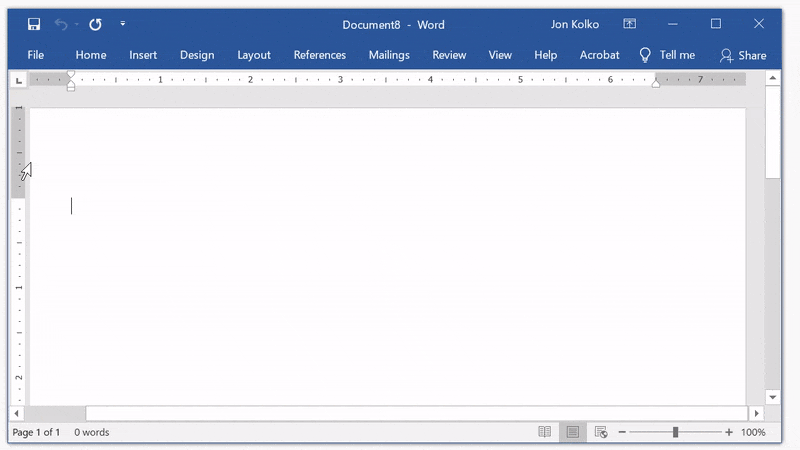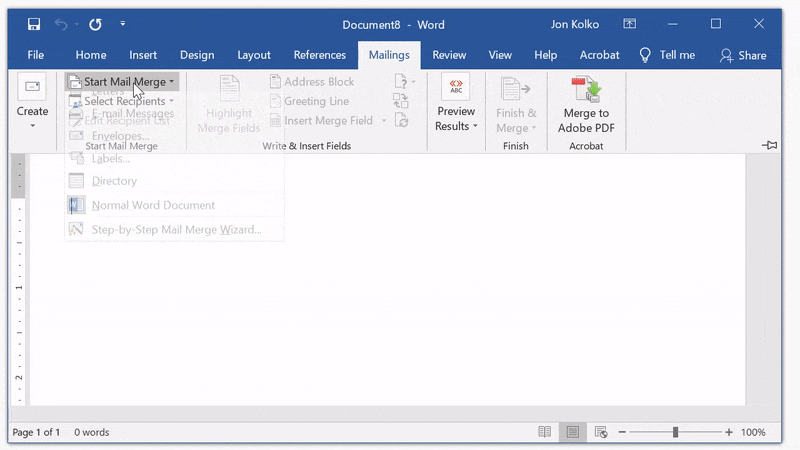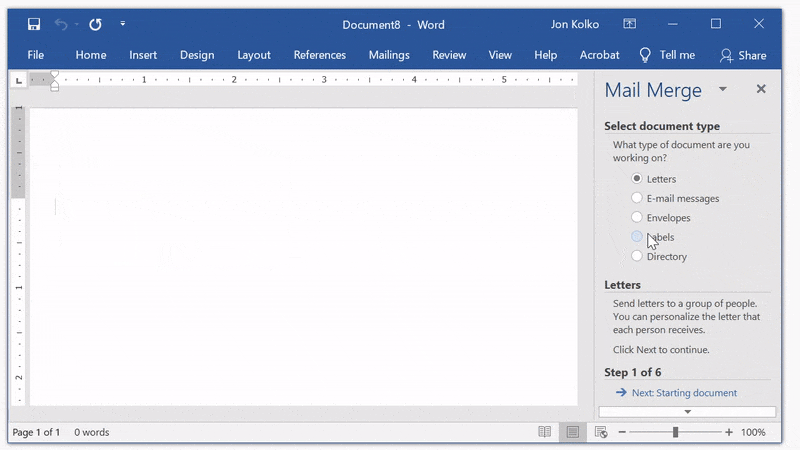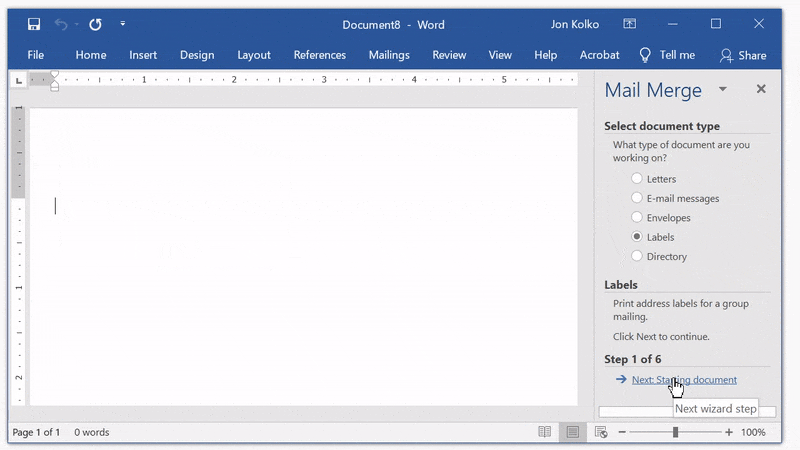
First, create a new document, go to the Mailings tab in the ribbon, and click Start Mail Merge. Use the Mail Merge Wizard and select Labels from the panel on the right.
Select your labels
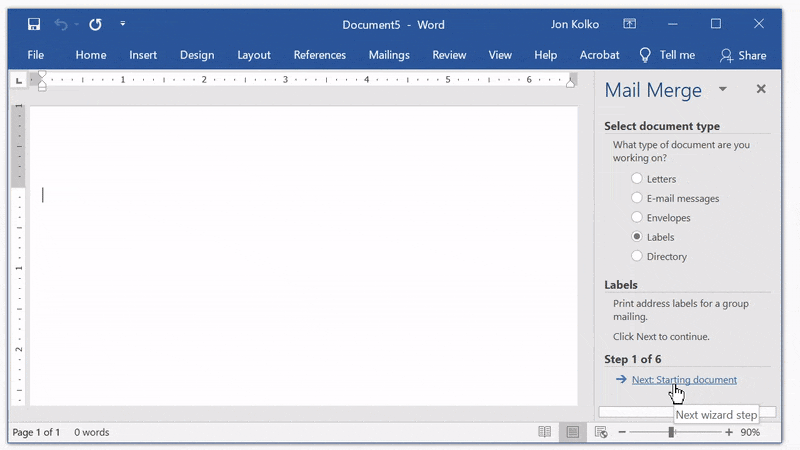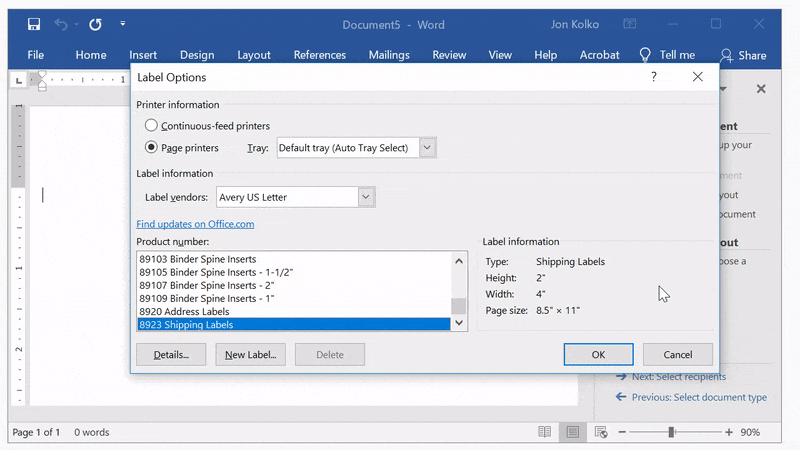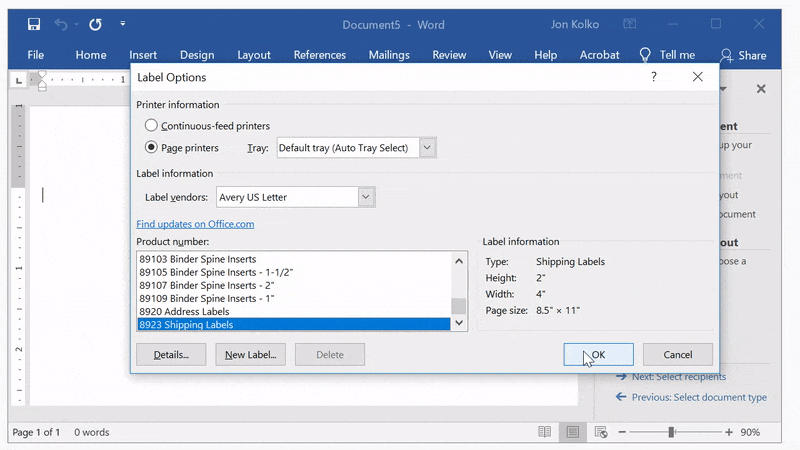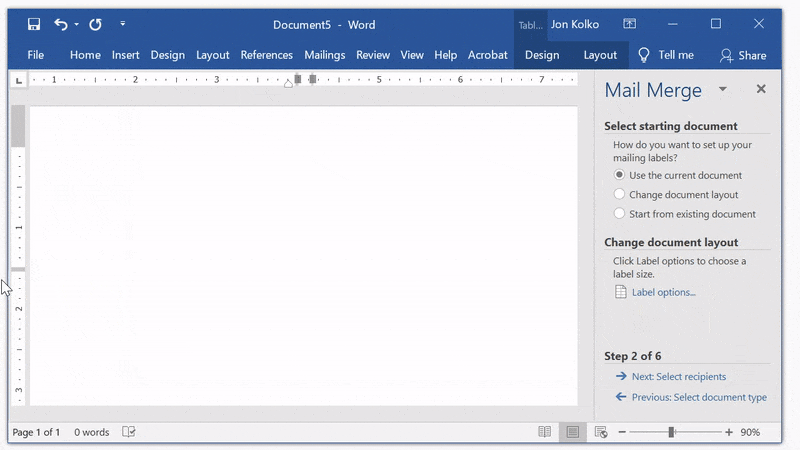
Click Next: Starting document and then on Label options on the right panel. If you were printing mailing labels, you would select a specific label type. We're going to use Avery's 8923 Shipping Labels as a template since the 4"x2" gives us enough room for rich content, but is still small enough to manipulate.
Click OK, and you'll see the document change to look like lots of small 4"x2" documents instead of one 8.5”x11” page.
Attach your Excel document
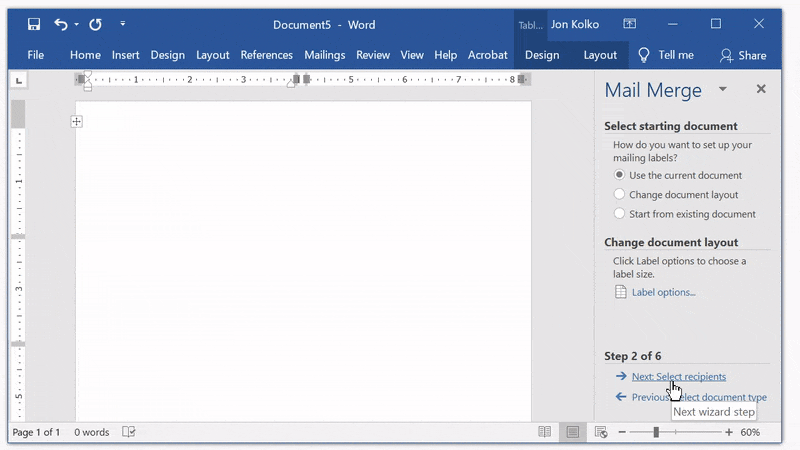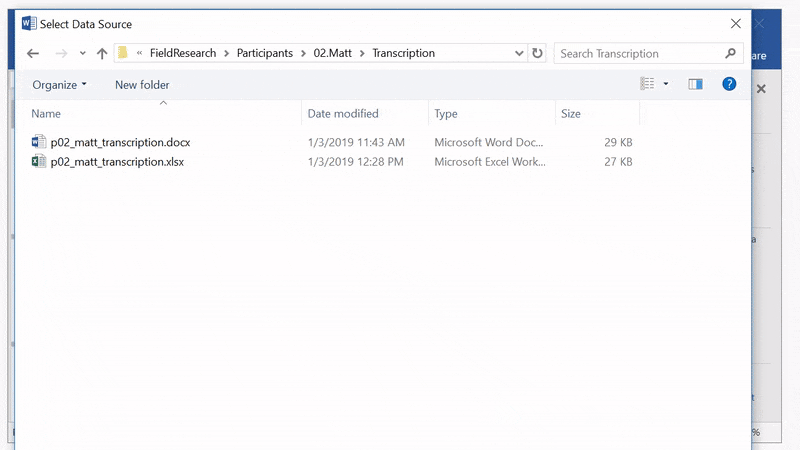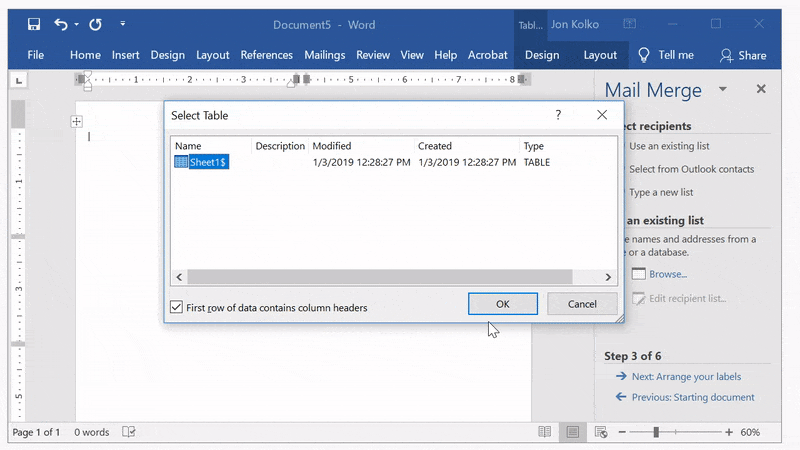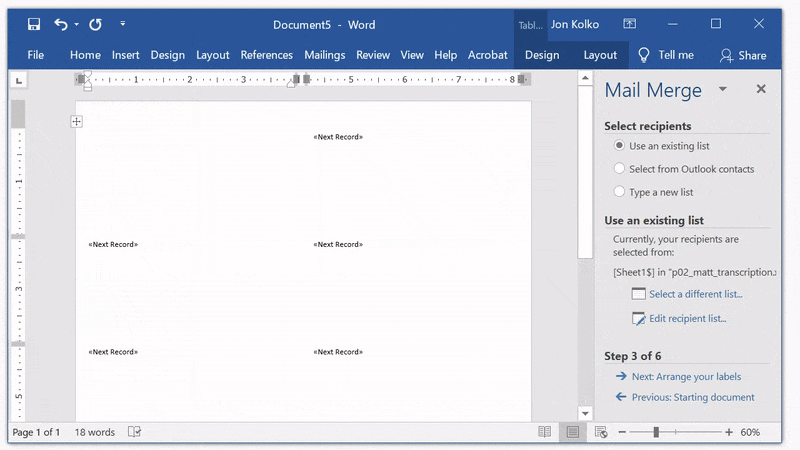
Click Next: Select recipients and then Browse... from the panel on the right. We will connect our Excel document by navigating to the Excel document we created. When prompted to Select a Table, click OK. Then, click OK in the following Mail Merge Recipients window.
You'll see “Next Record” on each label.
Insert your utterances
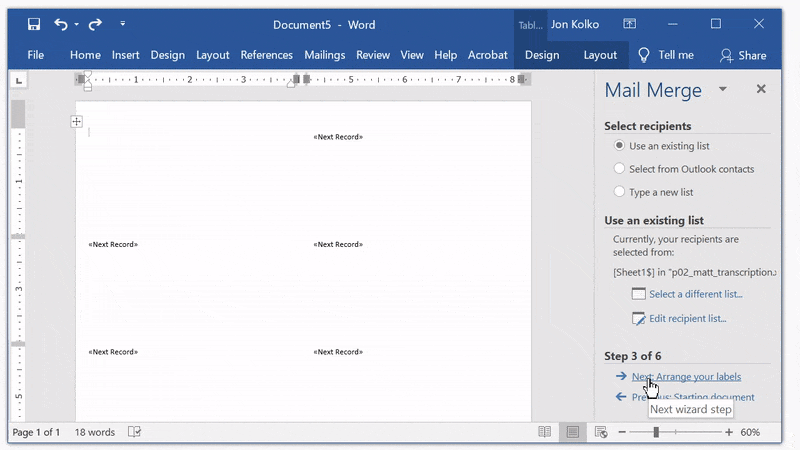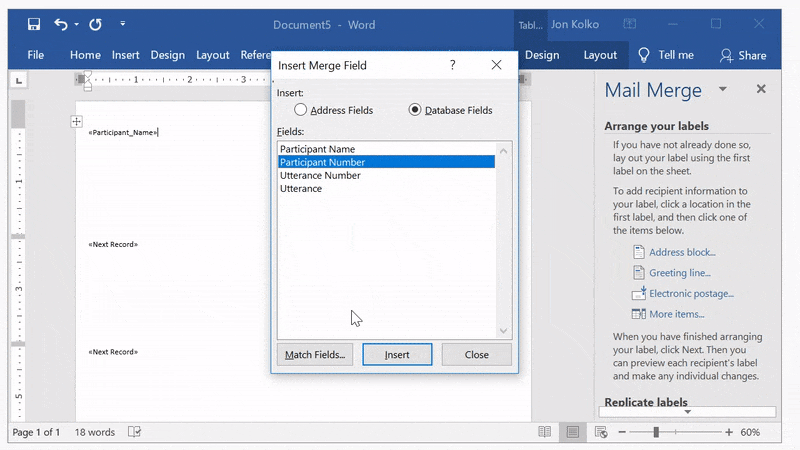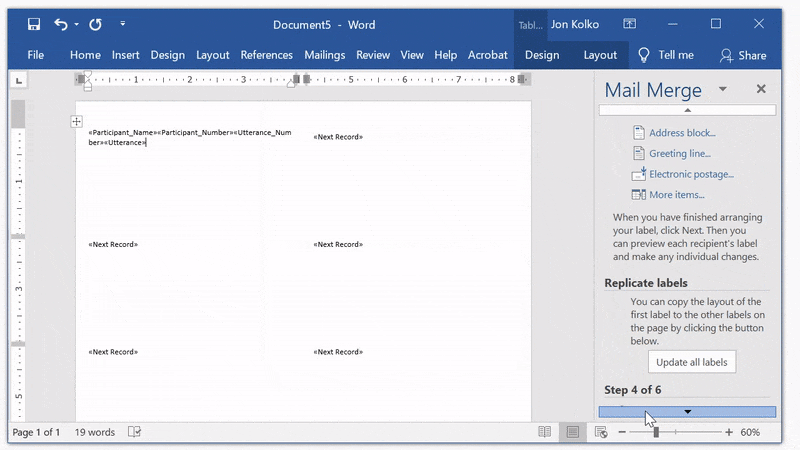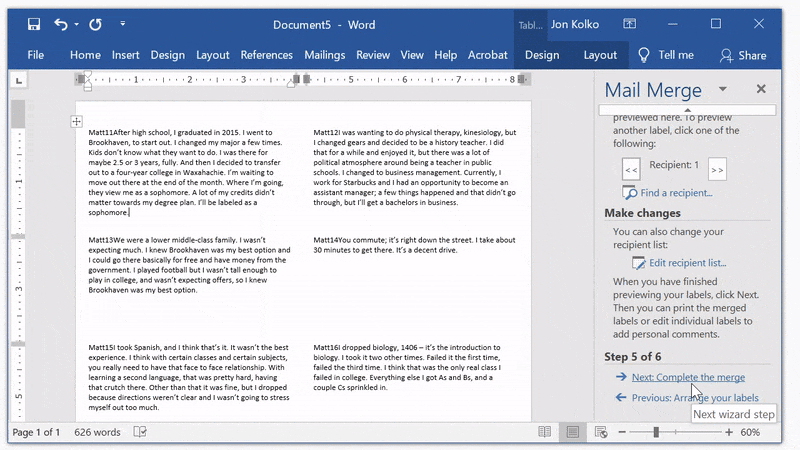
Click Next: Arrange your labels. Select More items... from the panel on the right and you'll see a window called Insert Merge Field. This lists all of the columns in your Excel document–Participant Name, Participant Number, Utterance Number, and Utterance.
Select each one and click Insert–you'll see them appear in the first label.
On the right panel, click Update all labels, and you'll see the content duplicate on each label.
Then, click Next: Preview your labels. All of our content is in the document and now we need to add formatting.
Arrange your content
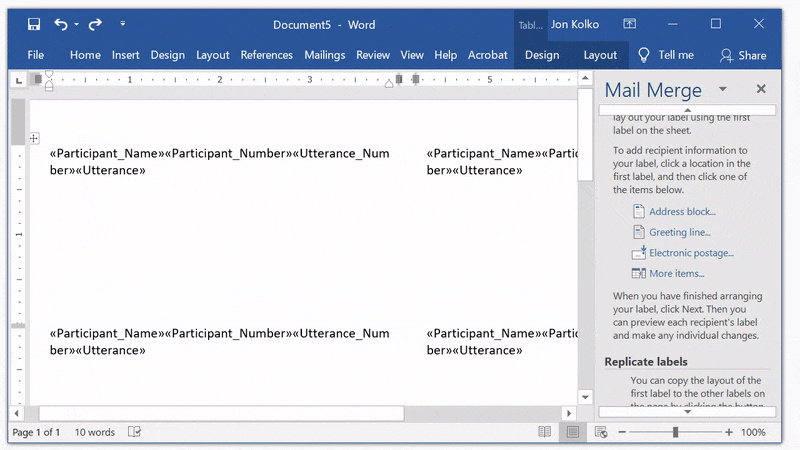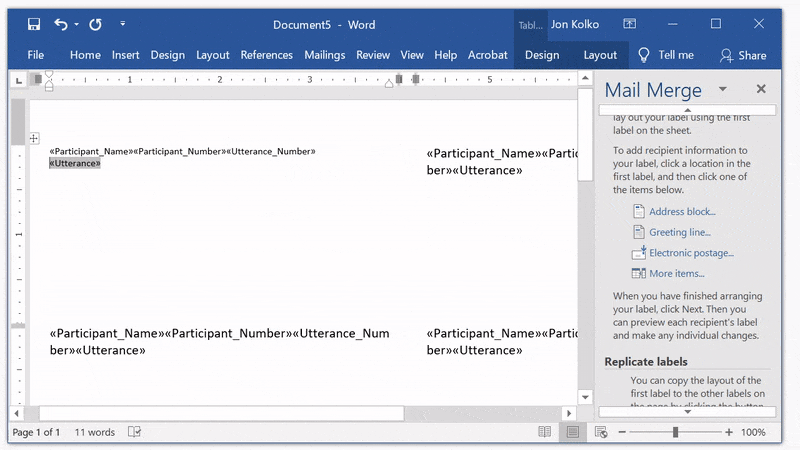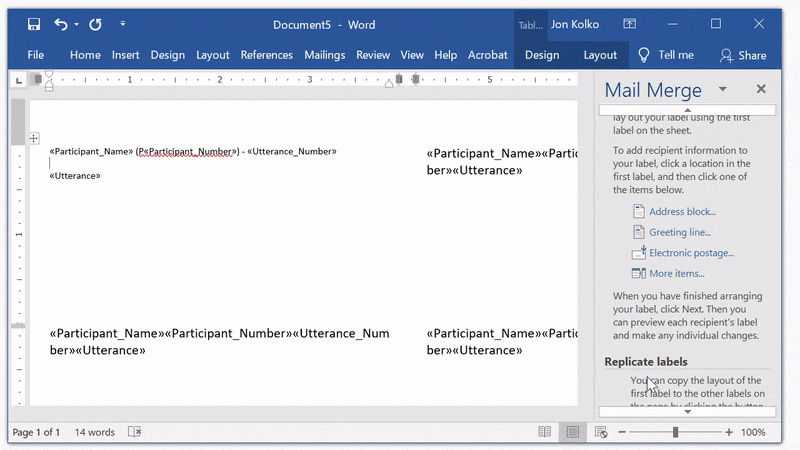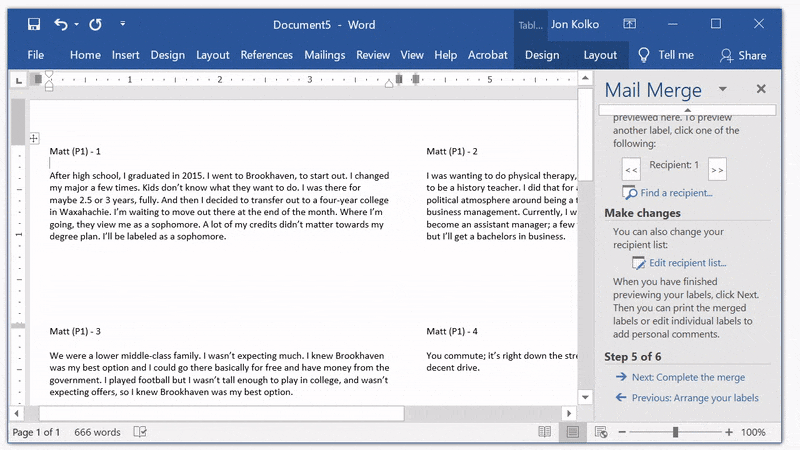
Click Previous: Arrange your labels to return to the Arrange screen.
You can edit this just like any other document. We use 8 point font so we can fit plenty of information on each card. Then, Click between «Participant_Name» and «Participant_Number», and add a space. We'll add the letter P before «Participant_Number» and a dash before «Utterance Number». Then, because «Utterance» is the most important part, add a full line break so it easily stands out.
Click Update all labels again, and then Next: Preview your labels.
Print the document
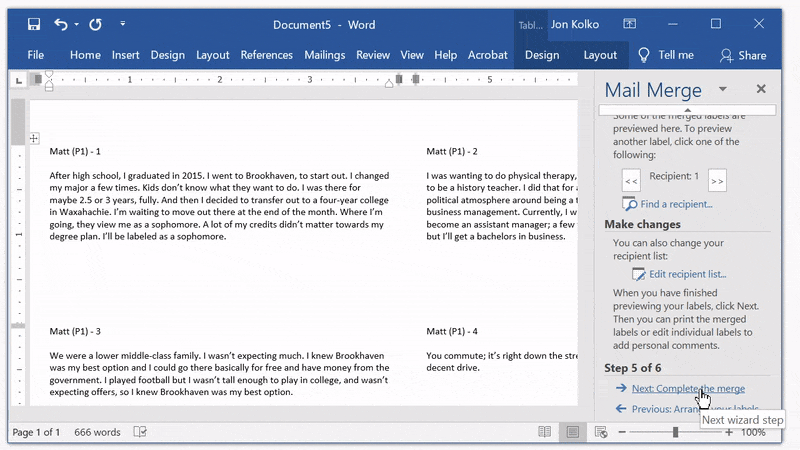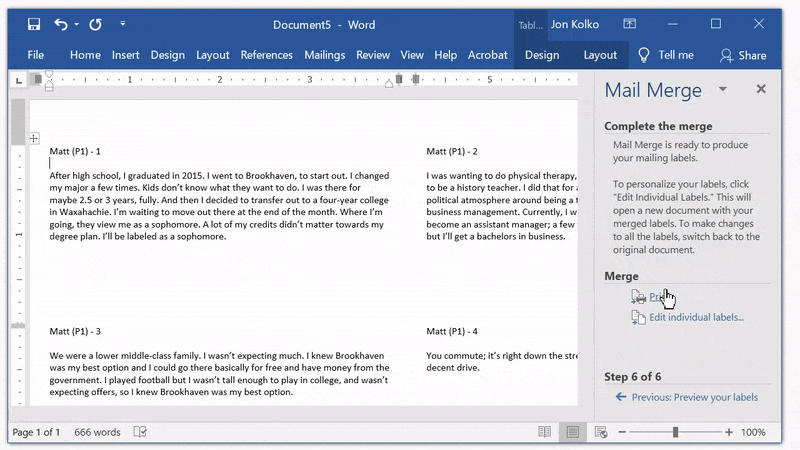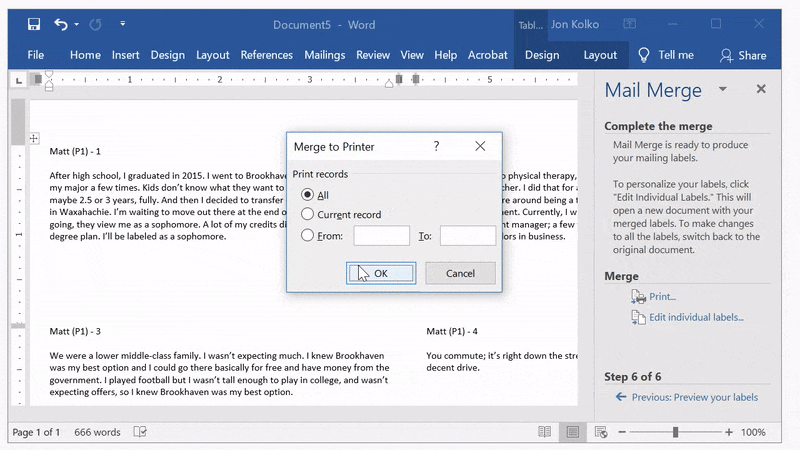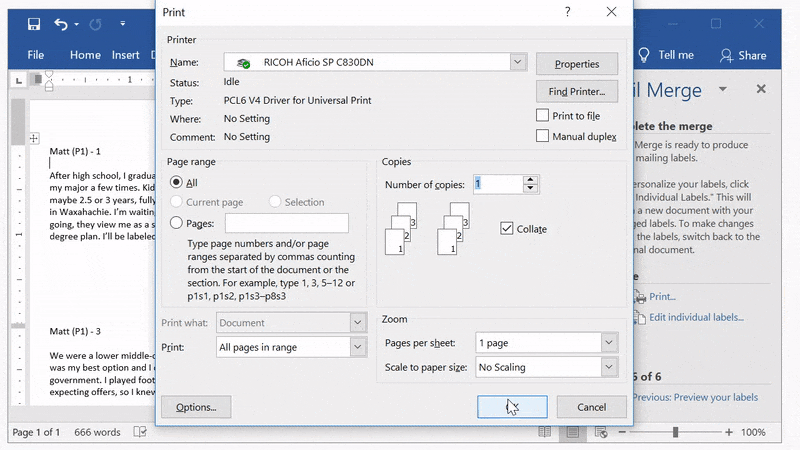
Click Next: Complete the merge and then print to both a printer and a .pdf file.
Put utterances on the wall
Print your utterances and use a paper cutter to cut them into individual cards—don’t worry about keeping them in order.

Now, we have an exact duplicate of all of our research content, but in a malleable, movable format. Our next step is to get all of the content on the wall so we can use it.
We use 8’x4’ black foam core that is 1/2" thick to hold our content. You can buy them at Uline and while they aren't cheap, they last for years. We prefer thumbtacks to attach the notes as permanent tape pulls the paper coating off and reusable tape tends to fall off overnight.
To attach the notes to the board, lay the board flat on the ground and literally crawl on it. This is much easier than putting the notes on the board when it is vertical, because you can minimize the time spent reaching for tacks. Every step counts when working with 4000 data points!
Each board can hold approximately 300 notes–a two-hour research interview will generate approximately 200 notes.
As we attach the notes to the board, we aren't worrying about keeping them in order or grouped by participant. Since the notes include attribution and citation, we can always find our way back to the context of the specific utterance.
Pictures on the wall
We photograph each of our research participants to trigger our memory about who is who later on. Once the utterances are complete, we print 8.5”x11” photos of all of our participants and display them on the wall along with their first name in big bold letters and two or three bullet points that describe the interview (“junior, majoring in math, works at Starbucks”).
Tracking our work
The research process is chaotic, requiring travel logistics, scheduling and rescheduling, and as many as three research sessions per day so we track our progress in a spreadsheet to make sure we don’t miss anything.
Our spreadsheet tracks each step described above: participant meta-data, scheduling, transferring the raw materials to the Dropbox, creating transcripts, and the utterance-development process.
Working through the mess
To synthesize the data, we follow a path from data to observations, and observations to inferences.
From data to observations
Now, it’s time to read each note, highlight salient or interesting comments, and place the notes on a new, blank board. When we find two notes that feel similar, we place them near one-another and over time, trends start to emerge.
When a grouping has about 5 or 6 utterances, we add a note at the top that describes the group, in the first person, such as, "I feel overwhelmed by my student debt."It’s easy to fall into the trap of what we call "red truck" matching:
- My dad drove a red truck, so that is why I drive one today. It reminds me of him.
- Every time I see a red truck, it reminds me of the hot-wheels toys that my brother and I used to play with.
There are a few ways to make meaning out of these similarities.
- One is to match the notes based on subject matter: they both contain a red truck therefore the notes are about driving red trucks.
- Another is to match them based on the behavior, feeling, or attitudes present: the notes are about how vehicles carry sentimental value.
The second method is much more useful because it starts to move past observation and into the world of inference. This is important so that we can provoke new considerations, not simply describe what already exists.
Once groups grow to 10 or 11 notes, we reassess and move some of the information into new groups or back into the larger mix in order to keep each group concise and specific. Over time, new patterns emerge and it’s necessary to continually evaluate where each note fits.

The wall will feel overwhelming at first, and it's difficult to start. Moving just 15 or 20 notes gives the wall a sense of purpose, making the task less intimidated. Don’t worry about getting it “right,” just dive in and start moving things around, knowing some of the information will moved again later on as you accumulate knowledge and refine your observation.
Throughout the process, it's helpful to clean up the boards so the unused group of notes are in neat columns and things don’t feel overly chaotic.
Many team members participate in this process, and it generally starts as a quiet, introspective, and personal activity: reading a note, considering it, and finding a place for it to live on the wall. Over time, conversation starts to pick up as the observations take shape. Humorous, emotional, or extreme utterances are often read aloud, and we’ll ask things like "Do we have a group about debt?" or "I thought we had something over in this area about student loans." Team members develop a tacit understanding of where things are geographically, and a semantic understanding of how topics are starting to emerge.
We timebox this activity based on our project schedule, which is often directly related to the amount of research that's been conducted. If it takes 3 weeks to conduct 20 participant interviews, this initial synthesis process will likely take another 1 to 2 weeks to gain traction. It's difficult to sustain attention for a full day so we’ll often work for a few hours and take a break, work on something else, or go for a walk to clear our heads and come back with a fresh perspective.
From observations to inferences
Once we have a critical mass of observations, we begin identifying inferences—combinations of observations around a given topic that are grouped by larger, more subjective leaps. Again, we avoid red truck matching and focus on behavior, feelings, and attitudes. At this stage, entire groupings are being moved around and placed in proximity of one-another and a meta-header will be created based on the inference about the overall content. For example:
Inference
College advisors are supportive, but in an effort to provide value, they often make decisions for students rather than with them. This reinforces a feeling of helplessness.
Observation
I have a personal relationship with my advisor.
Observation
My advisors understand the process.
Observation
My advisor acts like my mom and takes control.
The inference header moves from raw factual data into our interpretation of that data based on our perspectives and design expertise in human behavior, with the transcript data on hand to support the leap.
This is where "abductive thinking," an academic idea describing the 'logic of what might be,' starts to play a role.
While the initial data-to-observation process was generally quiet and introspective, the observation-to-inference process is a fully collaborative activity with inferences created, discussed, and debated by the group.
Inferences are magic, and contentious, introducing risk by making statements based on intuition rather than substantiated by fact. They shape the types of stories we are going to tell. Because there are infinite ways to interpret the content, we use group-driven sensemaking over three or four days. Sometimes it feels like we are going backwards, but during the last day or two we collectively unlock a strong understanding of the topic.
Getting organized for stories
To finish preparing to bring participant stories to life, we organize all of the material into a single, searchable master index.
First, combine all of the individual participant Excel spreadsheets into a single file. Copy and paste each into a workbook or use a VB script to get part of the way there for you.
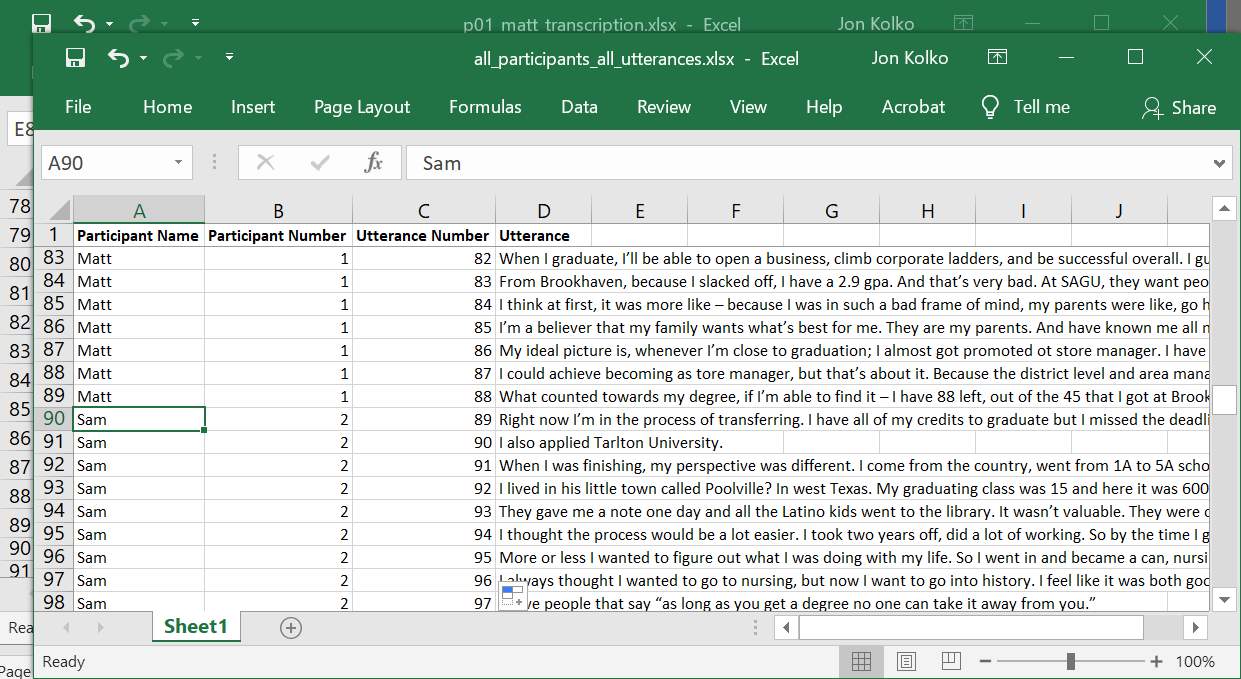
Now, add two columns between “Utterance Number” and “Utterance,” one for Inference Grouping and one for Observation Grouping. Using the citation numbers on the wall, add the group information to the spreadsheet. Start with a group on the top left corner of the wall and note the line number. Find the number in Excel (Ctrl-F) and add the observation statement and inference statement. Put a small dot on the physical note so you know you've processed it and move to the next note.
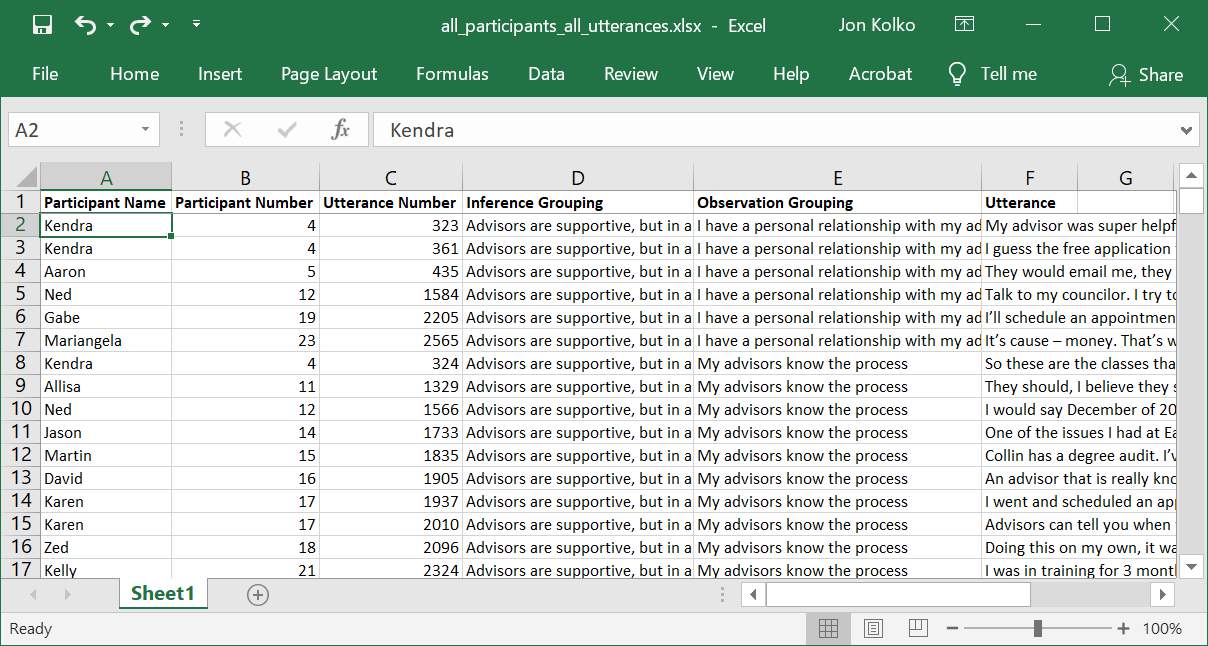
Auto-complete helps speed up this process, predicting which phrase you’re typing after you’ve added each theme or inference once.
Work your way through the entire wall of content until you have a single Excel spreadsheet with all of the data, organized as it appears on the wall.
Using the data
You've now developed a single, sortable, filterable artifact for building stories, which you can use to construct narratives, explain ideas, and describe strategic goals.
Imagine that you work at a bank and want to make changes to the monthly statement students receive about their loans. You can build a story about how debt creates a feeling of looming anxiety and use the material from your research to substantiate your argument, driving home your point emotionally, not just rationally.
To construct this story, you could search the spreadsheet for "debt" and find every mention or filter the inference column based on specific issues related to anxiety. Then, bring this content to life by talking about the person who said it, why they said it, and how they felt. You can even listen to their statements and use an audio clip in a presentation, so the audience hears the quote directly from the participant's mouth.
It's all about the details
Yes, the constant drumbeat in this tutorial is organization, doing things with care and structure so that when you get to the creative act of storytelling, you’re not hampered by logistics or overwhelmed by massive amounts of information. Through method and craft, you can bring your participants’ voices to the conversation and act as their advocate, quickly crafting strategic design stories to evangelize a position, communicate wants and needs, and tug at the heartstrings of your stakeholders in order to create real change.


